-
Avro?
Avro는 데이터를 컴퓨터가 이해하고 저장하거나 전송하기 쉬운 바이너리 형식으로 변환하는 JSON과 같은 역할을 하는 '데이터 직렬화 시스템'입니다. 직렬화/역직렬화 성능과 공간 효율성이 높아 특히 Hadoop, Kafka와 같은 빅데이터 처리 시스템에서 널리 사용됩니다.
- 특징:
- 스키마 기반: 데이터 구조를 JSON 형식으로 정의하는 스키마를 제공하여 데이터 유효성 검사 및 프로그램 간 호환성 보장
- 풍부한 데이이터 표현 구조: 기본적인 데이터 타입 뿐만 아니라 Enum, Arrays, Maps, Unions, Fixed 와 같은 구조도 기본 제공
- 컴팩트한 바이너리 형식: 데이터를 압축된 바이너리 형식으로 인코딩하여 저장 공간 절약 및 네트워크 전송 속도 향상
- 언어 독립성: 다양한 프로그래밍 언어(Java, C++, Python 등) 지원, 시스템 간 데이터 교환 용이
- 동적 스키마 진화: 새로운 필드 추가, 데이터 유형 변경 등 스키마 변경 허용, 시스템 변화에 유연하게 대응 Avro Schema Evolution Demystified: Backward and Forward Compatibility Explained
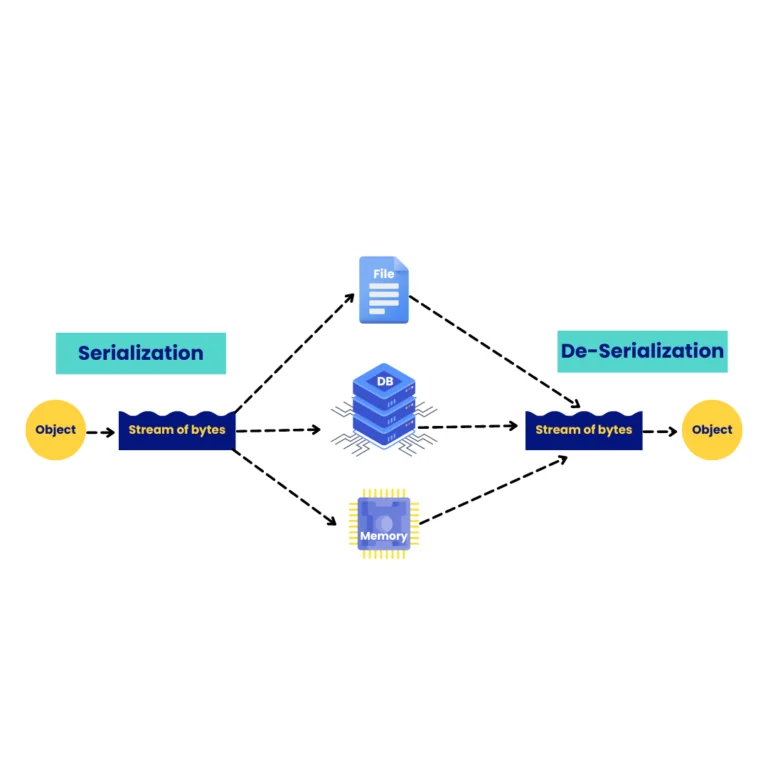
Avro는 스키마에 의존합니다. Avro 데이터를 읽을 때, 이를 쓸 때 사용된 스키마가 항상 존재합니다. 이를 통해 각 데이터를 값당 오버헤드 없이 쓸 수 있어 직렬화가 빠르고 작아집니다. 또한, 데이터와 스키마가 완전히 자체 설명적이므로 동적 스크립팅 언어와 함께 사용하기도 용이합니다.
Avro 데이터가 파일에 저장되면 스키마도 함께 저장되므로 나중에 모든 프로그램에서 파일을 처리할 수 있습니다. 데이터를 읽는 프로그램이 다른 스키마를 예상하는 경우 두 스키마가 모두 존재하므로 쉽게 해결할 수 있습니다스키마 예제
{ "name": "OrderCancelKafkaEvent", "namespace": "com.example.springkafkaavro.common.kafka.model", "type": "record", "fields": [ { "name": "odrderId", "type": "long" } ] }
Avro 작동 원리
- 바이너리 인코딩: 데이터를 컴팩트한 바이너리 형식으로 변환하여 저장 및 전송 효율성 극대화
- 스키마 활용: JSON(*.avsc) 형식의 스키마를 통해 데이터 구조 정의 및 데이터와 함께 저장하거나 별도 관리 가능
Avro 활용 분야
- 빅데이터 처리: 하둡, 카프카 등 빅데이터 시스템에서 데이터 저장 및 전송
- RPC(원격 프로시저 호출): 시스템 간 데이터 교환
- 데이터 저장: 데이터 웨어하우스, 데이터 레이크 등 데이터 저장
실무자를 위한 자료
A Benchmark of JSON-compatible Binary Serialization Specifications
A Survey of JSON-compatible Binary Serialization Specifications
Putting Avro into Hive
Benchmarking Performance of Data Serialization and RPC Frameworks in Microservices Architecture: gRPC vs. Apache Thrift vs. Apache Avro
Apache Avro
Object serialization vs relational data modelling in Apache Cassandra: a performance evaluationRef
'시리즈 > Avro' 카테고리의 다른 글
Avro Gradle source, outputDir (사용자 지정) (0) 2024.10.02 Avro Gradle Plugin (디폴트 설정) (2) 2024.10.02 Avro VS JSON (2) 2024.10.02 댓글
- 특징: